Run in Postman
インポートを開始する
インポートを開始するには、POSTリクエストを/crm/v3/importsに送信します。その際、インポートファイルの列をHubSpot上の関連するプロパティーに割り当てる方法をリクエスト本文で指定します。
APIインポートはform-dataタイプのリクエストとして送信され、リクエスト本文には次のフィールドが含まれます。
- importRequest:リクエストのJSONを格納するテキストフィールド。
- files:インポートファイルを格納するファイルフィールド。
multipart/form-dataの値が含まれるContent-Typeヘッダーを追加します。
以下のスクリーンショットは、Postmanなどのアプリを使用したリクエストの例です
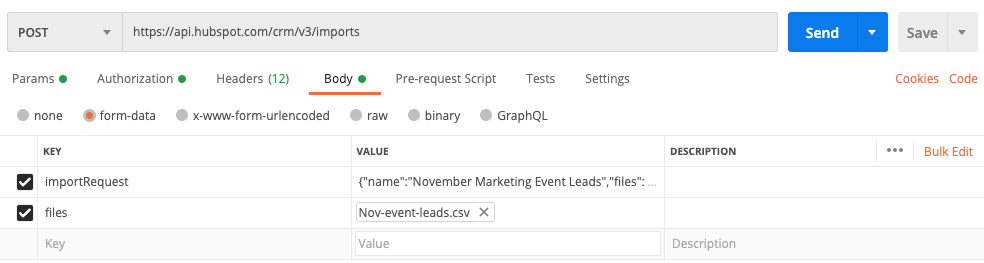
importRequestデータを書式設定する
リクエストでは、インポートファイルの詳細(スプレッドシートの列のHubSpotデータに対するマッピングなど)を定義します。また、次のフィールドを含める必要があります。- name:インポートの名前。これはHubSpot上で、リストなどの他のツールで参照できる名前で、インポートツールにも表示される名前です。
- importOperations:この任意指定のフィールドを使用して、インポートで特定のオブジェクトやアクティビティーのレコードの作成と更新、作成のみ、または更新のみのいずれを行うかを指示します。オブジェクト/アクティビティーの
objectTypeIdを指定し、レコードのUPSERT(作成と更新)、CREATE、またはUPDATEを行いたいかどうかを指定します。例えばリクエストのフィールドは次のようになります:"importOperations": {"0-1": "CREATE"}このフィールドを含めない場合、インポートに使用されるデフォルト値はUPSERTです。 - dateFormat:ファイルに含まれる日付の形式。これは既定では
MONTH_DAY_YEARに設定されていますが、DAY_MONTH_YEARまたはYEAR_MONTH_DAYも使用できます。 - marketableContactImport:インポートファイルに含まれるコンタクトのマーケティングステータスを示す任意指定のフィールド。これは、マーケティングコンタクトの利用が可能なアカウントにコンタクトをインポートする場合にのみ使用します。ファイル内のコンタクトをマーケティング対象として設定するには、
trueの値を使用します。ファイル内のコンタクトをマーケティング対象外として設定するには、falseの値を使用します。 - createContactListFromImport:インポートからコンタクトの静的リストを作成するための任意指定のフィールド。ファイルからリストを作成するには、
trueの値を使用します。 - files:インポートファイルの情報を格納する配列。
- fileName:インポートファイルの名前。
- fileFormat:インポートファイルの形式。CSVファイルの場合に使用する値は
CSVです。Excelファイルの場合に使用する値はSPREADSHEETです。 - fileImportPage:インポートファイルのデータをHubSpotデータにマッピングするために必要な
columnMappings配列が含まれます。列のマッピングの詳細については、以下で説明しています。
HubSpotプロパティーにファイルの列をマッピングする
columnMappings配列内には、スプレッドシートの列ヘッダーの順序に合わせて、インポートファイルの各列に対応するエントリーを含めます。
各列には、次のフィールドを格納します。
- columnObjectTypeId: データが属するオブジェクトまたはアクティビティーの名前または
objectTypeId値。objectTypeId値の一覧については、こちらの記事をご覧ください。 - columnName: 列ヘッダーの名前。これは、ファイルの列ヘッダーの名前に完全一致する必要があります。
- propertyName: データのマッピング先となるHubSpotプロパティーの内部名。
toColumnObjectTypeIdフィールドが使用されている場合、複数ファイルのインポートで共通する列では、propertyNameがnullである必要があります。 - columnType:これを使用して、列に固有IDプロパティーが含まれることを指定します。インポートのプロパティーと目標に応じて、次のいずれかの値を使用します。
- HUBSPOT_OBJECT_ID: レコードのID。例えば、コンタクトのインポートファイルに、コンタクトに関連付けられる会社のIDを格納する「レコードID」列を含めるケースが考えられます。_ _
- HUBSPOT_ALTERNATE_ID: レコードID以外の固有ID。例えば、コンタクトのインポートファイルに、コンタクトのEメールアドレスを格納した「Eメール」列を含めるケースが考えられます。_ _
- FLEXIBLE_ASSOCIATION_LABEL:関連付けラベルが列に含まれることを示すには、この列タイプを含めます。
- ASSOCIATION_KEYS:同じオブジェクト関連付けインポートの場合にのみ、関連付けられる同じオブジェクトレコードの固有IDにこの列タイプを含めます。例えば、連絡先の関連付けをインポートするリクエストでは、「Associated contact [email/Record ID]」列の
columnTypeをASSOCIATION_KEYSにする必要があります。_ _詳しくは、同じオブジェクト関連付けインポート用にインポートファイルを設定する方法についてご確認ください。
- toColumnObjectTypeId:複数のファイルまたは複数のオブジェクトをインポートする場合の、共通する列プロパティーまたは関連付けラベルが属するオブジェクトの名前または
objectTypeId。プロパティーが属していないオブジェクトのファイルに共通する列プロパティー用にこのフィールドを含めます。例えば、共通する列として[Eメール]コンタクトプロパティーを持つ2つのファイルのコンタクトと会社を関連付ける場合、会社ファイルの「Eメール」列用にtoColumnObjectTypeIdを含めます。_ __ _ - foreignKeyType:
associationTypeIdとassociationCategoryで指定された、共通の列が使用する関連付けのタイプ(複数ファイルのインポートの場合のみ)。プロパティーが属していないオブジェクトのファイルに共通する列プロパティー用にこのフィールドを含めます。例えば、共通する列として[Eメール]コンタクトプロパティーを持つ2つのファイルのコンタクトと会社を関連付ける場合、会社ファイルの「Eメール」列用にforeignKeyTypeを含めます。_ __ _ - associationIdentifierColumn:レコードを関連付けるために共通の列で使用されるプロパティーを示します(複数ファイルのインポートの場合のみ)。プロパティーが属しているオブジェクトのファイルに共通する列プロパティー用にこのフィールドを含めます。例えば、共通する列として[Eメール]コンタクトプロパティーを持つ2つのファイルのコンタクトと会社を関連付ける場合、会社ファイルの「Eメール」列について
associationIdentifierColumnをtrueに設定します。_ __ _
1つのオブジェクトを含む1つのファイルをインポートする
以下は、1つのファイルをインポートしてコンタクトを作成するためのリクエスト本文の例です。- JSON
複数のオブジェクトを含む1つのファイルをインポートする
以下は、1つのファイル内のコンタクトと会社をインポートしてラベルに関連付けるためのリクエスト本文の例です。- JSON
複数のファイルをインポートする
以下は、2つのファイル内のコンタクトと会社をインポートして関連付けるためのリクエスト本文の例です。コンタクトプロパティー[Eメール]__がファイル内の共通の列です。- JSON
importIdを含むレスポンスが返されます。完了すると、インポートをHubSpotで表示できますが、ビュー、リスト、レポート、またはワークフローでインポートを基準にレコードを絞り込む際には、API経由で完了したインポートをオプションとして使用することはできません。
以前のインポートを取得する
HubSpotアカウントから全てのインポートを取得するには、/crm/v3/imports/にGETリクエストを送信します。特定のインポートの情報を取得するには、/crm/v3/imports/{importId}にGETリクエストを送信します。
インポートを取得すると、インポートの名前、ソース、ファイル形式、言語、日付形式、列マッピングなどの情報が返されます。また、インポートのstateも返されます。これは次のいずれかである可能性があります。
STARTED:HubSpotはインポートが存在することを認識していますが、インポートの処理はまだ開始されていません。PROCESSING:インポートがアクティブに処理されています。DONE:インポートは完了済みです。全てのオブジェクト、アクティビティー、または関連付けが更新または作成されました。FAILED:インポートの開始時に検出されなかったエラーがありました。インポートは完了しませんでした。CANCELED:エクスポートがSTARTED、PROCESSING、DEFERREDのいずれかの状態だったときに、ユーザーがエクスポートをキャンセルしました。DEFERRED:最大数(3件)のインポートが同時に処理されています。他のインポートの1つの処理が終了すると、インポートが開始されます。
インポートをキャンセルする
インポートをキャンセルするには、/crm/v3/imports/{importId}/cancelにPOSTリクエストを送信します。
インポートエラーの意味とトラブルシューティング
特定のインポートのエラーを表示するには、/crm/v3/imports/{importId}/errorsにGETリクエストを送信します。典型的なインポートエラーとその解決方法で詳細をご確認ください。
「列数が正しくありません」、「JSONを解析できません」」、「このURLは解析できません」、「404 text/htmlは受け付けられません」などのエラーが返された場合は、次のようにします。
- ファイル内の各列に列ヘッダーがあり、リクエスト本文に各列の
columnMappingエントリが含まれていることを確認します。次の条件を満たしている必要があります。- リクエスト本文とインポートファイルの列の順序は一致していなければなりません。列の順序が一致しない場合、自動的な並べ替えの試行に失敗し、インポートの開始時にエラーが発生する可能性があります。
- 全ての列がマッピングされていなければなりません。列がマッピングされていない場合でもインポートリクエストは成功する可能性がありますが、インポートの開始時に「列数が正しくありません」というエラーが発生する場合もあります。
- ファイルの名前がリクエストのJSONの
fileNameフィールドと一致していて、fileNameフィールドにファイル拡張子が含まれていることを確かめてください(例:import_name.csv)。 multipart/form-dataの値のあるContent-Typeがヘッダーが含まれていることを確かめます。